swift-developers-japan
main / atcoder



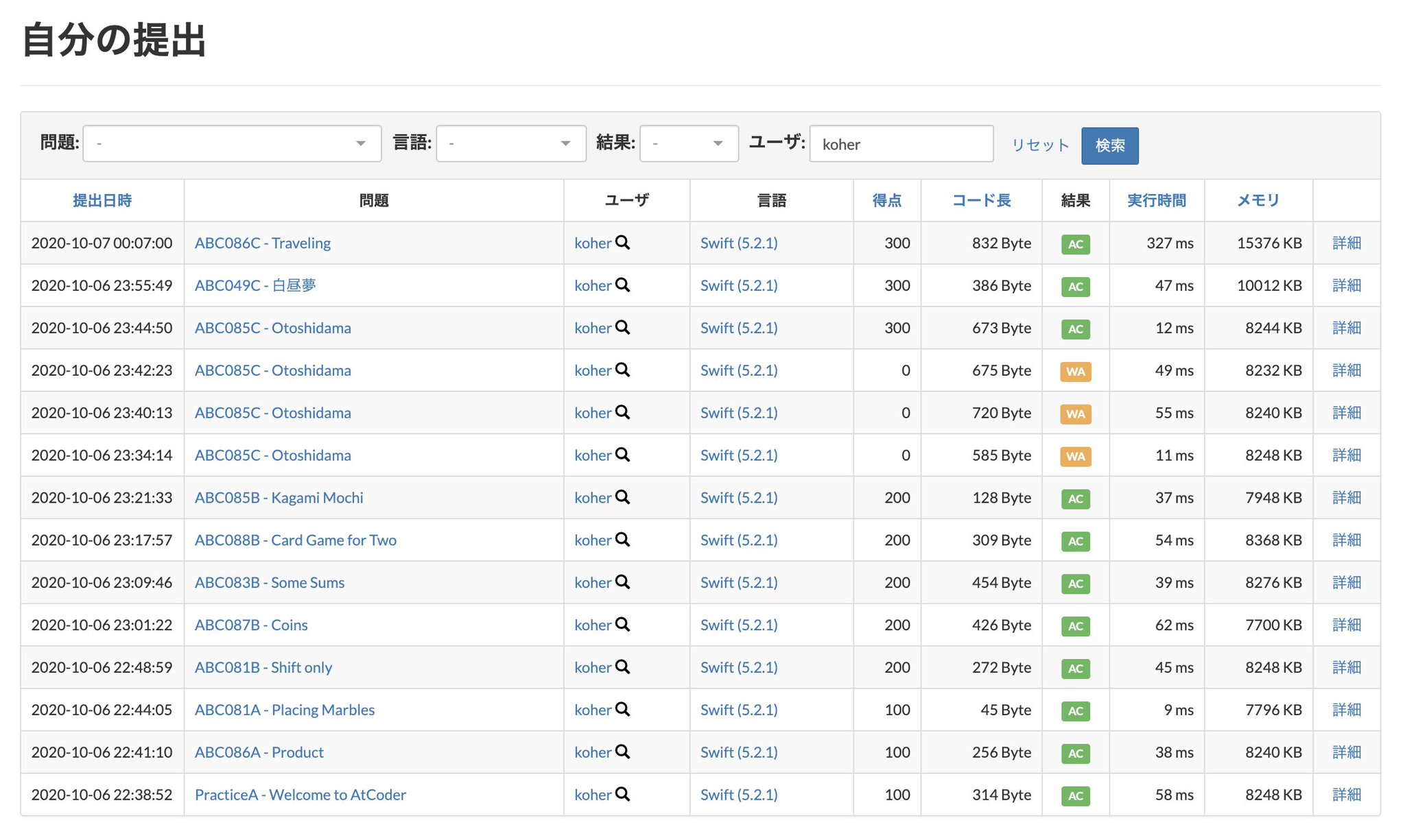

 1
1

Set 使うよりも Array を使った方が速かったです。 Set だと 375 ms 、 Array だと 354 ms 。 Set 版: https://atcoder.jp/contests/hhkb2020/submissions/17324446 Array 版: https://atcoder.jp/contests/hhkb2020/submissions/17324417
% つけないといけなくて面倒で、 1 ≤ A, B, C ≤ 10^9 で、積の和を計算するので、とてもじゃないけど 64 bit じゃ収まらないです。% 前の値を出力させてみたら↓でした。 1858445835049782285757026664950217712384527500000000% の計算が必要になります。なので、あまり変わらないかなと。BigInt が使えれば同じことができるんですが・・・。2 ** (2 ** (2 ** (2 ** 2)))Decimal で同じことできるかと思ったんですが、 pow の第 2 引数に Decimal を渡せないのでダメでした・・・。
BigInt ↓これはあるんですが https://github.com/dankogai/swift-pons

BigInt 作るか・・・。
BigInt 必要と感じたことはないんですよね。-Ounchecked だから実行時エラーにならないのか。BigInt よりも ModInt を作りました。こっちで計算しておけば常に % で余りとってくれるので問題ないです。 BigInt では無理な桁数も扱ってくれるし。 https://github.com/koher/swift-atcoder-support/blob/main/Sources/AtCoderSupport/ModInt.swift
998244353 この値はなんですか?なんか競技プログラミングではよく出てくる値みたいですけど。modulus を書き換えて使うという荒業ですw1000000007 とかもよく使われるみたいです。% だと結果が負になってしまうので、そこのケアも ModInt でやってます。%+ とか %- とか作ろうかと思ったんですが、型にしました。%+ とかの方が用途に合ってるかもしれません。 


 https://twitter.com/koher/status/1352765051568943105?s=21
https://twitter.com/koher/status/1352765051568943105?s=21
 1
1
 kyoprobu です。
kyoprobu です。  ABC 191 は個人戦です。コンテスト中に他人とコミュニケーションを取ることはできません。本イベントはコンテスト終了後に開催します。 # Swift と競プロ 競技プログラミングにおける Swift 使用人口は多くありません。だからこそ、 Swift 競プロerで集まってわい...
ABC 191 は個人戦です。コンテスト中に他人とコミュニケーションを取ることはできません。本イベントはコンテスト終了後に開催します。 # Swift と競プロ 競技プログラミングにおける Swift 使用人口は多くありません。だからこそ、 Swift 競プロerで集まってわい... 1
1
print(D < V * T || V * S < D ? "Yes" : "No") で算出しました
print(!(v*t...v*s).contains(d) ? "Yes" : "No") にしてみました!! を付けることで消えていないときに "Yes" を出しているのですねprint(aa.filter { $0 != X } .map { String($0) } .joined(separator: " ")) で算出しました

")

 おつかれさまでした!
おつかれさまでした! お疲れ様でした
お疲れ様でした

// Paste a sample input here var stdinString: [String] = """ 42782.4720 31949.0192 99999.99 <- ここに標準入力の内容を貼り付ける """.split(separator: "\n").map(String.init).reversed() public func readLine() -> String? { stdinString.popLast() }")




 1 1
1 1  1
12... でループするってやってないですね。 @swift-5.2.5
let n = 10000000000 var aa: Set<Int> = [] for a in 2... { if a * a > n { break } aa.insert(a) } print(aa.sorted().last!) (edited) 4
4 https://kenkoooo.com/atcoder#/list/ 1
https://kenkoooo.com/atcoder#/list/
https://engineer-lab.findy-code.io/redcoder
https://kenkoooo.com/atcoder#/list/ 1
https://kenkoooo.com/atcoder#/list/
https://engineer-lab.findy-code.io/redcoder kyoprobuでやってます。ABC出た方他にもいらっしゃればご自由にどうぞ。 https://twitter.com/koher/status/1390973068940431376 (edited)
kyoprobuでやってます。ABC出た方他にもいらっしゃればご自由にどうぞ。 https://twitter.com/koher/status/1390973068940431376 (edited)
numbers.filter(\.isEven)extension Int { var isEven: Bool { isMultiple(of: 2) } } print([2, 3, 5].filter(\.isEven)) let n = 5 var sumToCount: [Int: Int] = [:] for i in 1 ... n { for j in 1 ... n { for k in 1 ... n { let sum = i + j + k sumToCount[sum, default: 0] += 1 } } } for sum in sumToCount.keys.sorted() { print(sum, sumToCount[sum]!) }
3 1 4 3 5 6 6 10 7 15 8 18 9 19 10 18 11 15 12 10 13 6 14 3 15 1let n = readInt1() let aa = readIntN() var aToCount: [Int: Int] = [:] for a in aa { aToCount[a % 200, default: 0] += 1 } var ans = 0 for count in aToCount.values { ans += count * (count - 1) / 2 } print(ans) var a = true a.toggle() print(a)
 2
2 https://twitter.com/algo_method/status/1427602147525361675?s=19
https://twitter.com/algo_method/status/1427602147525361675?s=19 https://twitter.com/the_uhooi/status/1427625425010823191?s=19
https://twitter.com/the_uhooi/status/1427625425010823191?s=19
 1
1

 1
https://twitter.com/algo_method/status/1427602147525361675?s=19
https://gist.github.com/koogawa/4a2de9795dc0a045dfe066fd47b867cb
1
https://twitter.com/algo_method/status/1427602147525361675?s=19
https://gist.github.com/koogawa/4a2de9795dc0a045dfe066fd47b867cb 1
1
1
1
pow((1-sqrt(5))/2, N) が出てきますがこれって計算量どうなるんですっけ
import Foundation func original(n: Int, x: Int, y: Int) -> Int { var (n, x, y) = (n, x, y) for _ in 2 ..< n { let t = (x + y) % 100 x = y y = t } return y } struct Mat { var m11: Double var m12: Double var m21: Double var m22: Double init(_ m11: Double, _ m12: Double, _ m21: Double, _ m22: Double) { self.m11 = m11 self.m12 = m12 self.m21 = m21 self.m22 = m22 } static func * (lhs: Mat, rhs: Mat) -> Mat { Mat( lhs.m11*rhs.m11 + lhs.m12*rhs.m21, lhs.m11*rhs.m12 + lhs.m12*rhs.m22, lhs.m21*rhs.m11 + lhs.m22*rhs.m21, lhs.m21*rhs.m12 + lhs.m22*rhs.m22 ) } } func mat(n: Int, x: Int, y: Int) -> Double { let S = Mat( -(1+sqrt(5))/2, -(1-sqrt(5))/2, 1, 1 ) let Jn = Mat( pow((1-sqrt(5))/2, Double(n-2)), 0, 0, pow((1+sqrt(5))/2, Double(n-2)) ) let St = Mat( -1 / sqrt(5), (5-sqrt(5)) / 10, 1 / sqrt(5), (5+sqrt(5)) / 10 ) let m = S * Jn * St let num = Double(x) * m.m12 + Double(y) * m.m22 return num - floor(num/100)*100 } print(original(n: 60, x: 2, y: 3), mat(n: 60, x: 2, y: 3)) print(original(n: 80, x: 2, y: 3), mat(n: 80, x: 2, y: 3))81 81.00830078125 91 64.0 1let aa = readLine()!.split(separator:" ").map { Int(String($0))! }let aa = readLine()!.split(separator: " ").map { Int($0)! } 1append() するより init(repeating:count:) で最初に確保するほうがパフォーマンスがいいのでしょうか?dp.last! で強制アンラップしていますが、 dp[N - 1] でインデックスを使えば ! は不要ですね、、動的計画法 1-2 について Xcode(Mac でしか動作しない IDE)のコンソールに入力例をコピペするとエラーになります。VSCode に貼ってからコピペし直すとうまくいくようなので、文字コードなどの問題かもしれません。 また、入力例を貼り付けたあとに自分で Enter キーを押下しないといけないのも地味に手間です。AtCoder では自動で Return まで入力されたので、同じ仕様だと嬉しいです。 1
append() するより init(repeating:count:) で最初に確保するほうがパフォーマンスがいいのでしょうか?  1
1
append() するより init(repeating:count:) で最初に確保するほうがパフォーマンスがいいのでしょうか? 1
dp.last! で強制アンラップしていますが、 dp[N - 1] でインデックスを使えば ! は不要ですね、、 ! 不要ですが、 Array に [i] でアクセスするのは ! 使ってるのと同じ( ! の nil も [i] の範囲外も Logic Failure )なので、どちらが良いかと言われると微妙ですね。 1
append でのバッファの確保は倍々に行われるので、バッファの allocate およびコピーの計算量がその長さに比例するとした場合、最終的に N 要素分の領域を確保するための計算量は reserveCapacity してもしなくても O(N) になります。もちろんそれでも reserveCapacity した方が定数倍速いんですが、競プロの問題は定数倍が原因で TLE になることは稀であり、成績を残すには速く解くことが重要なので、このようなケースでは reserveCapacity はほぼ必要ないと考えています。
 2
2
 を表明しない限り大丈夫です
を表明しない限り大丈夫です 1 1 1 1
)参加者を募ってやってみましょー! 1
1 1 1 1
)参加者を募ってやってみましょー! 1 1
1cin >> cout << hoge << endl; みたいな書き方にもだんだん慣れてきましたwlet N = Int(readLine()!)! を cpp で書くと int N; cin >> N;std::scanf std::printf 派もいるみたいです(こっちのほうが正統?) (edited)print(hoge) は cout << hoge << endl

componentsSeparatedByString とか、普通に英文として読めるstringByAddingPercentEncodingWithAllowedCharacters: とかも > 長いのint main() { cout << "Hello" << "World!"; return 0; } int main() { cout << "Hello" << "World!" << endl << "hahaha"; return 0; }
 1
1 代表 → @sak_algo コンテンツ → @sak_algo + @drken1215 デザイン → @yukino_works
代表 → @sak_algo コンテンツ → @sak_algo + @drken1215 デザイン → @yukino_works
 のちほどコメントにて訂正させてください。ご指摘ありがとうございます! (Swift の追加は現在開発班で検討中のため、もうしばらくお待ちいただけると幸いです。いつも問題を解いてくださりありがとうございます)
3
https://twitter.com/semisagi/status/1430463417949704198?s=19
のちほどコメントにて訂正させてください。ご指摘ありがとうございます! (Swift の追加は現在開発班で検討中のため、もうしばらくお待ちいただけると幸いです。いつも問題を解いてくださりありがとうございます)
3
https://twitter.com/semisagi/status/1430463417949704198?s=19 5
5 2
2
Fatal error: Range requires lowerBound <= upperBound
") ♂️ 2 #アルゴ式
♂️ 2 #アルゴ式
 #アルゴ式
#アルゴ式
 2
2 

 ABC ヌーヴォー ABC212: 非常に高いレベル(橙上位 Diff) ABC213: 50 回に 1 回のレベル(ABC 史上 4 回目の赤 Diff) ABC214: 歴史にないほどのレベル(ABC 史上最高 Diff 更新) ABC215: 過去最高と言われた前回に迫るレベル ABC216: 過去最高レベルと言われた前回・前々回を超えるレベル 2
ABC ヌーヴォー ABC212: 非常に高いレベル(橙上位 Diff) ABC213: 50 回に 1 回のレベル(ABC 史上 4 回目の赤 Diff) ABC214: 歴史にないほどのレベル(ABC 史上最高 Diff 更新) ABC215: 過去最高と言われた前回に迫るレベル ABC216: 過去最高レベルと言われた前回・前々回を超えるレベル 2print("row: \(row), column: \(column), dp: \(dp)") #アルゴ式
 1
1

 #アルゴ式
#アルゴ式
 1 2 1
1 2 1 4 2
4 2  4
4memo[rbg] でキャッシュのディクショナリにアクセスしていますが、 memo の要素を 1 つずつ取り出し、ヒット率が悪くなれば打ち切る、ということですね ヒット率のしきい値をきれいに求められれば有効そう…? 1memo はメソッドが呼び出される度に使い捨ててるので、空間計算量のオーダーも変わってないですし特に問題なさそうですね(超巨大な画像で、メモリを数倍使ったらアウトとかいう状況でなければ)。 1 1
https://t.co/LB5QRB7D0x #アルゴ式


 2
2 2
2  2
2 3
3
3
3
 2 2 1 )
https://t.co/aIlwJoz2QJ #アルゴ式
2 2 1 )
https://t.co/aIlwJoz2QJ #アルゴ式
 1 2
https://t.co/UsAA64u8Rp #アルゴ式
1 2
https://t.co/UsAA64u8Rp #アルゴ式


 1 3
1 3 1 1
1 1 5 2 3 2
5 2 3 2 1
2 2 2 ずらしていただいたのに...
1
2 2 2 ずらしていただいたのに...
 2 1 ! ) )
2 1 ! ) )  1 1 1 #アルゴ式“
1 1 1 #アルゴ式“ 3 2
3 2
 7
7
 #毎日アルゴ式 4
https://t.co/YfYRAkfQxI #アルゴ式 https://t.co/heWpVlhi6t
#毎日アルゴ式 4
https://t.co/YfYRAkfQxI #アルゴ式 https://t.co/heWpVlhi6t



 ) 1
) 1 

 2 3
2 3  1
1  3 事業について どのような事業をするのか 皆さまから見えているサービスであるアルゴ式(beta)ではなく、開発中のB2B SaaSプラットフォームである「アルゴ式 for busin
3 事業について どのような事業をするのか 皆さまから見えているサービスであるアルゴ式(beta)ではなく、開発中のB2B SaaSプラットフォームである「アルゴ式 for busin 3 5
3 5 https://atcoder.jp/contests/abc249/tasks/abc249_c 1
https://atcoder.jp/contests/abc249/tasks/abc249_c 1Array2D 、 Array3D 、ArrayND を作って使っています。 https://github.com/koher/swift-atcoder-support/blob/main/Sources/AtCoderSupport/Array2D.swift 1 (edited) (edited)
(edited) 2
2 
 1
1
 1
1 (a + b - 1) / b でa / bの切り上げができるっていうのおもしろい。
 1
1 (普通にfloorしてから必要ならintにしてました) 1 1
(普通にfloorしてから必要ならintにしてました) 1 1 import Foundation extension Int { func cbrt() -> Int { Int(pow(Double(self), 1 / 3)) // global の pow が呼ばれると思ってた... } func pow(fakeSignature: Void) { // こっちは引数が違うから呼ばれないと思ってた... } } print(2023.cbrt())
import Foundation extension Int { func cbrt() -> Int { Int(pow(Double(self), 1 / 3)) // global の pow が呼ばれると思ってた... } func pow(fakeSignature: Void) { // こっちは引数が違うから呼ばれないと思ってた... } } print(2023.cbrt()) <stdin>:5:13: error: use of 'pow' refers to instance method rather than global function 'pow' in module 'SwiftGlibc' Int(pow(Double(self), 1 / 3)) ^ <stdin>:5:13: note: use 'SwiftGlibc.' to reference the global function in module 'SwiftGlibc' Int(pow(Double(self), 1 / 3)) ^ SwiftGlibc. SwiftGlibc.pow:1:13: note: 'pow' declared here public func pow(_ __x: Double, _ __y: Double) -> Double ^
import Foundation extension Int { func cbrt() -> Int { Int(pow(Double(self), 1 / 3)) // global の pow が呼ばれると思ってた... } func pow(fakeSignature: Void) { // こっちは引数が違うから呼ばれないと思ってた... } } print(2023.cbrt()) <stdin>:5:9: error: type '()' cannot conform to 'BinaryInteger'; only struct/enum/class types can conform to protocols Int(pow(Double(self), 1 / 3)) ^ <stdin>:5:9: note: required by initializer 'init(_:)' where 'T' = '()' Int(pow(Double(self), 1 / 3)) ^ <stdin>:5:33: error: extra argument in call Int(pow(Double(self), 1 / 3)) ~~^~~ <stdin>:5:17: error: cannot convert value of type 'Double' to expected argument type 'Void' Int(pow(Double(self), 1 / 3)) ^import Foundation extension Int { func cbrt() -> Int { Int(SwiftGlibc.pow(Double(self), 1 / 3)) } func pow(fakeSignature: Void) {} } print(2023.cbrt())
import Foundation extension Int { func cbrt() -> Int { Int(SwiftGlibc.pow(Double(self), 1 / 3)) } func pow(fakeSignature: Void) {} } print(2023.cbrt()) 12
import Foundation extension Int { func cbrt() -> Int { Int(SwiftGlibc.pow(Double(self), 1 / 3)) } func pow(fakeSignature: Void) {} } print(2023.cbrt()) 12 import Foundation func task() -> Bool { let N = 2 let S = ["b", "m"] let T = ["m", "d"] var ans = true var words = Set<String>() var g = [String: String]() for i in 0..<N { g[S[i]] = T[i] words.insert(S[i]) words.insert(T[i]) } var done = Set<String>() var seen = Set<String>() func rec(_ v: String) { seen.insert(v) guard let next = g[v] else { return } if seen.contains(next) { if !done.contains(next) { ans = false return } } rec(next) done.insert(v) } for v in words where !seen.contains(v) { rec(v) } return ans } func task2() { var TRUE = 0, FALSE = 0 for _ in 0..<10000 { switch task() { case true: TRUE += 1 case false: FALSE += 1 } } print("TRUE: \(TRUE), FALSE: \(FALSE)") } for _ in 0..<10 { task2() }
import Foundation func task() -> Bool { let N = 2 let S = ["b", "m"] let T = ["m", "d"] var ans = true var words = Set<String>() var g = [String: String]() for i in 0..<N { g[S[i]] = T[i] words.insert(S[i]) words.insert(T[i]) } var done = Set<String>() var seen = Set<String>() func rec(_ v: String) { seen.insert(v) guard let next = g[v] else { return } if seen.contains(next) { if !done.contains(next) { ans = false return } } rec(next) done.insert(v) } for v in words where !seen.contains(v) { rec(v) } return ans } func task2() { var TRUE = 0, FALSE = 0 for _ in 0..<10000 { switch task() { case true: TRUE += 1 case false: FALSE += 1 } } print("TRUE: \(TRUE), FALSE: \(FALSE)") } for _ in 0..<10 { task2() } TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000 TRUE: 0, FALSE: 10000
import Foundation func task() -> Bool { let N = 2 let S = ["b", "m"] let T = ["m", "d"] var ans = true var words = Set<String>() var g = [String: String]() for i in 0..<N { g[S[i]] = T[i] words.insert(S[i]) words.insert(T[i]) } var done = Set<String>() var seen = Set<String>() func rec(_ v: String) { seen.insert(v) guard let next = g[v] else { return } if seen.contains(next) { if !done.contains(next) { ans = false return } } rec(next) done.insert(v) } for v in words where !seen.contains(v) { rec(v) } return ans } func task2() { var TRUE = 0, FALSE = 0 for _ in 0..<10000 { switch task() { case true: TRUE += 1 case false: FALSE += 1 } } print("TRUE: \(TRUE), FALSE: \(FALSE)") } for _ in 0..<10 { task2() } TRUE: 3333, FALSE: 6667 TRUE: 3333, FALSE: 6667 TRUE: 3334, FALSE: 6666 TRUE: 3333, FALSE: 6667 TRUE: 3333, FALSE: 6667 TRUE: 3334, FALSE: 6666 TRUE: 3333, FALSE: 6667 TRUE: 3333, FALSE: 6667 TRUE: 3334, FALSE: 6666 TRUE: 3333, FALSE: 6667  2
2
-Ounchecked でもいいんじゃないですか?と口を出したらそのまま採用されてしまったという・・・。そのせいで何度も苦しめられました (edited) 3.upToNextMinor になってるの、 .upToNextMajor が良いような気がしますね。マイナーバージョンアップは API の追加であって破壊的変更はないので。 dependencies: [ .package( url: ""https://github.com/apple/swift-collections.git"", .upToNextMinor(from: ""1.0.0"") // or `.upToNextMajor ), .package(url: ""https://github.com/apple/swift-algorithms.git"", .upToNextMinor(from: ""1.0.0"")) ], 3 1 3
3 1 3  https://t.co/xl7MmgHwCc #アルゴ式
https://t.co/xl7MmgHwCc #アルゴ式
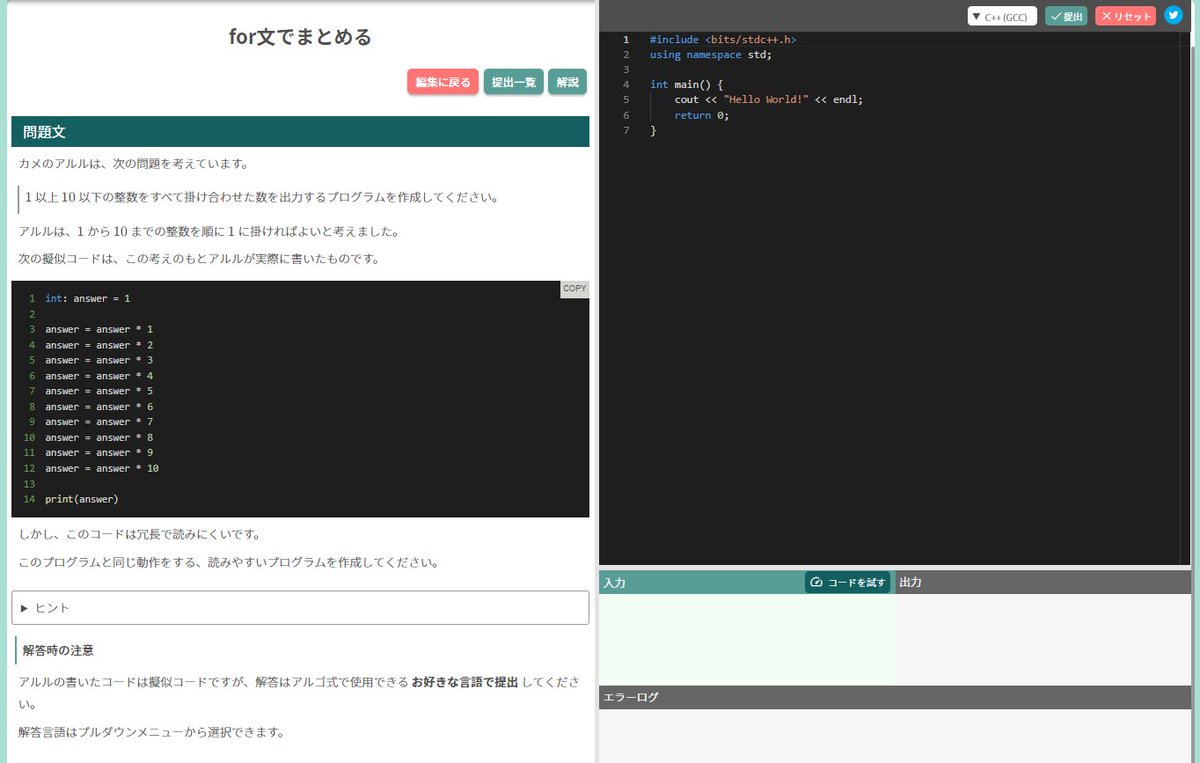 #アルゴ式 #アルゴ式
#アルゴ式 #アルゴ式 1
1 1 2
1 2
 1 ) 1 1 3 1 2
1 ) 1 1 3 1 2
 1 1 1 2
1 1 1 2  1
1 https://x.com/algo_method/status/1763881941017706843 アルゴ式 7月ごろにbetaが外れるそうです
https://x.com/sak_algo/status/1776786039375556884 (edited)
https://t.co/ISzJGjkzCD #アルゴ式
https://x.com/algo_method/status/1763881941017706843 アルゴ式 7月ごろにbetaが外れるそうです
https://x.com/sak_algo/status/1776786039375556884 (edited)
https://t.co/ISzJGjkzCD #アルゴ式
 2 1
2 1 1 1
3
1 1
3 1 2 1 1
1 2 1 1  1 1 2 1 1 1 1 1
1 1 2 1 1 1 1 1  1 1 1 2 1 1 1 1 1
1 1
1 1
1 1 1 2 1 1 1 1 1
1 1
1 1 ️ (edited)
️ (edited) 1 2 4
1 2 4 1 1
1 1 1 1
1 1 1
1

 1
1
 3
3
")



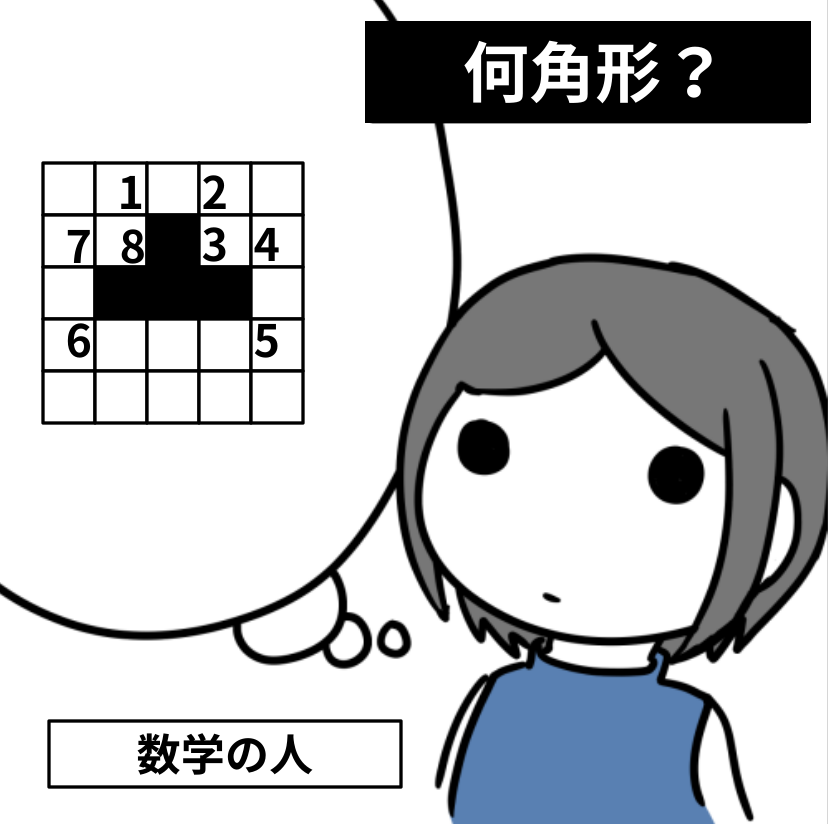
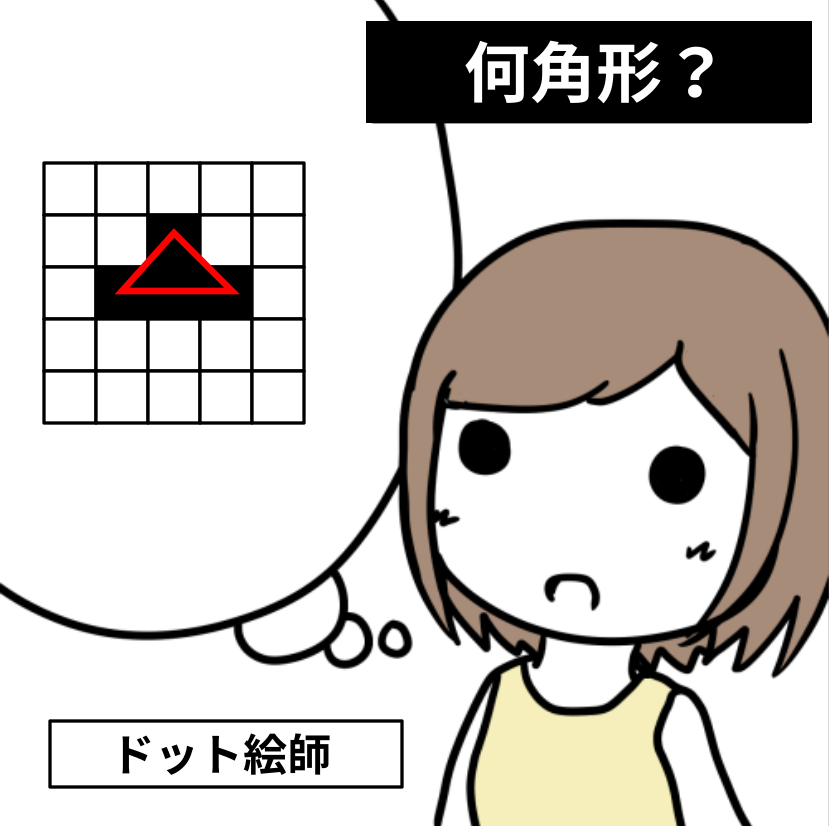
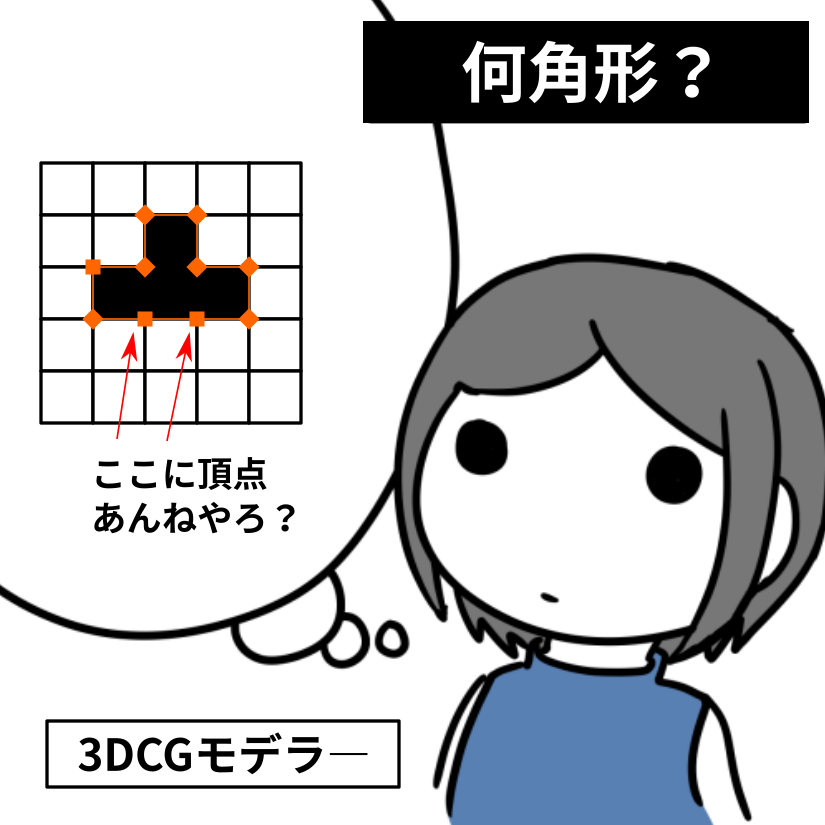


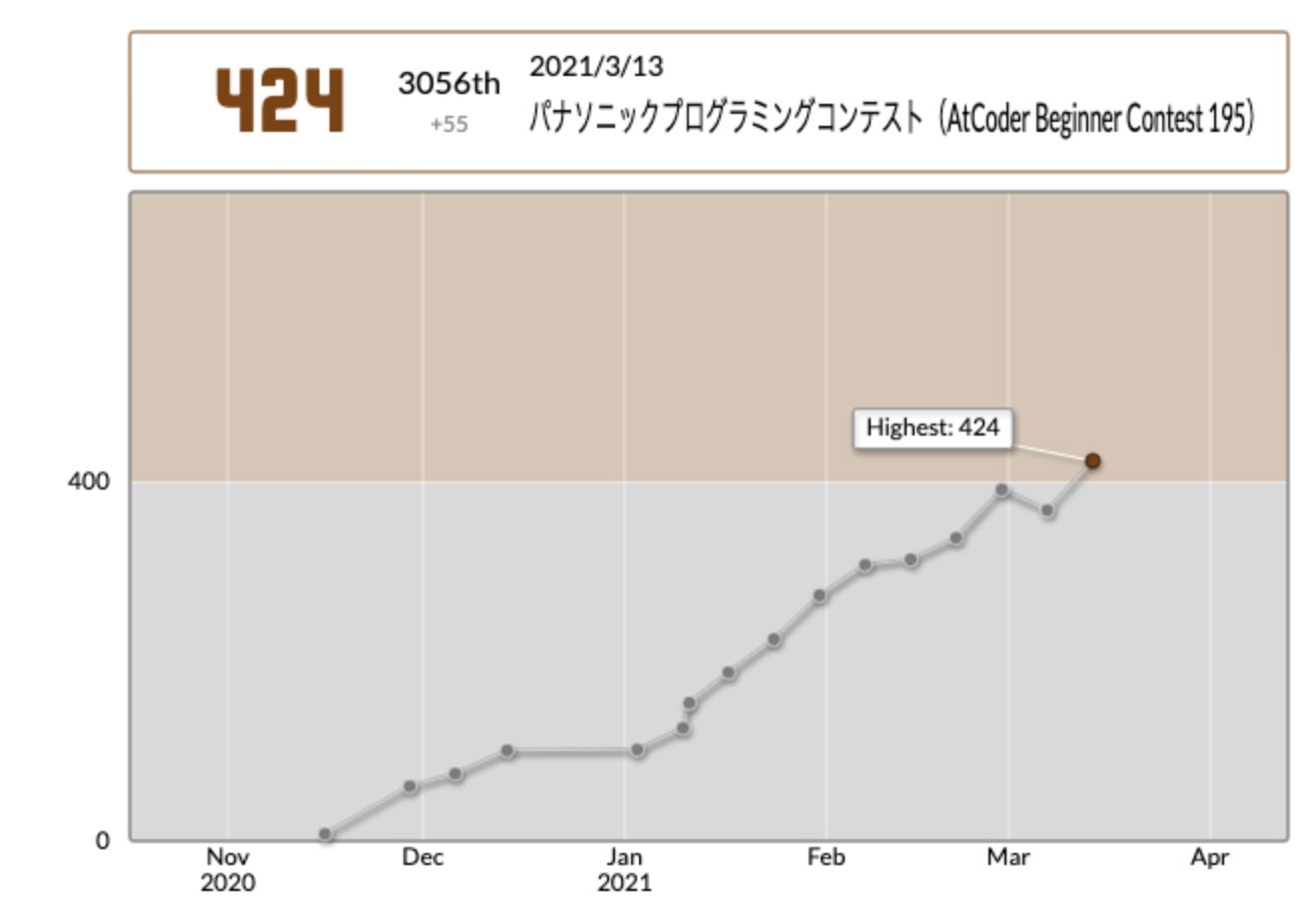




")
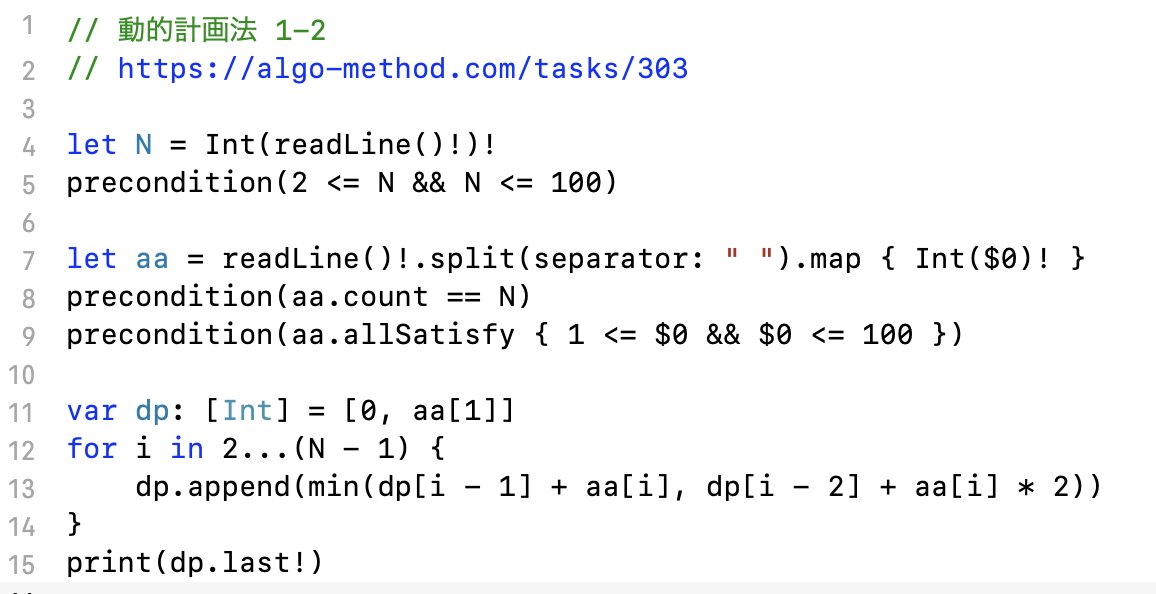




")
")



")










")







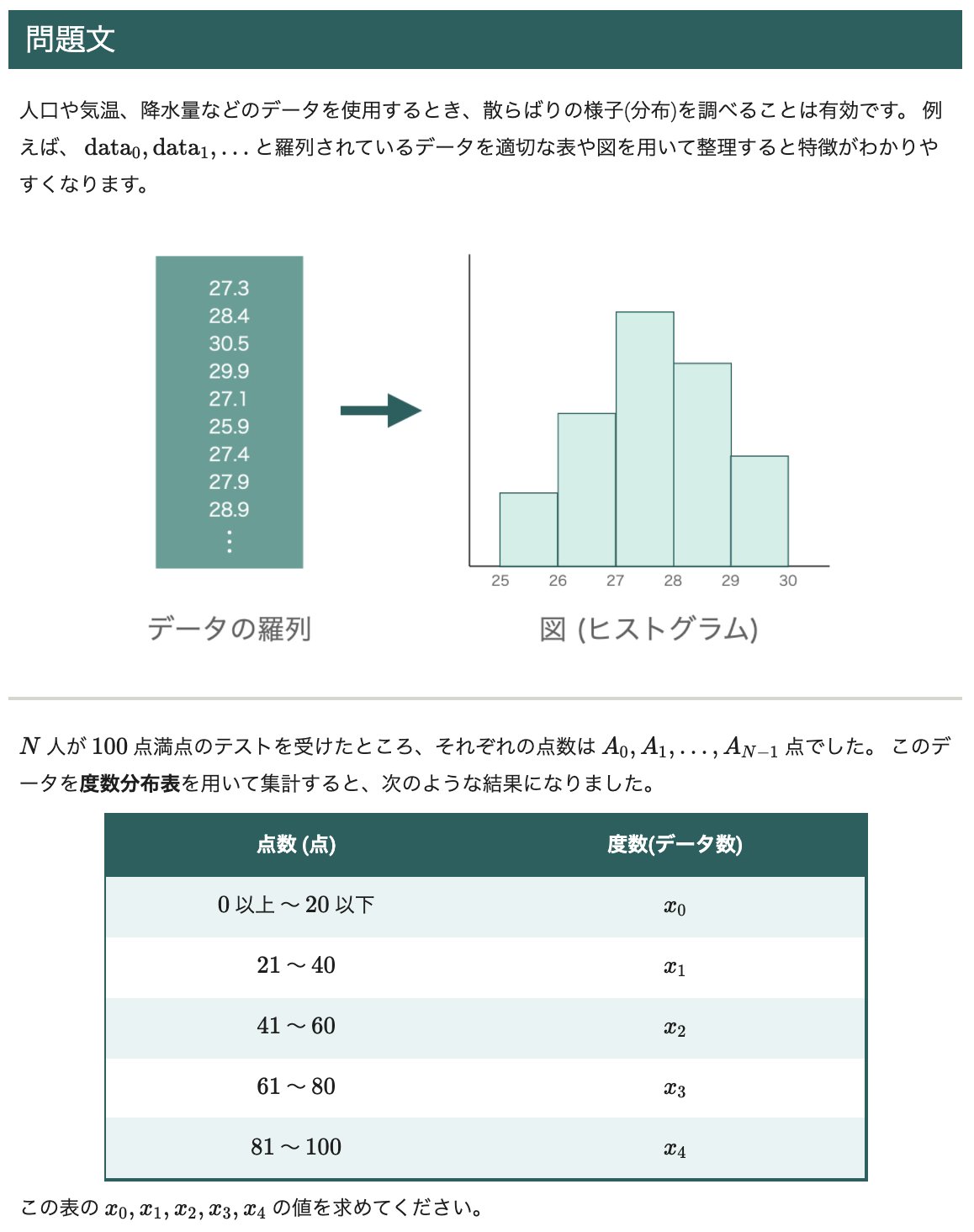
 の問題のようです
の問題のようです 













